Ο Γιάννης Ασσαέλ τελείωσε πρώτος στο master του στο πανεπιστήμιο της Οξφόρδης, και τώρα είναι διδακτορικός φοιτητής σε μια από τις καλύτερες ομάδες τεχνητής νοημοσύνης (artificial intelligence AI). Υπεύθυνοι του εργαστηρίου του είναι οι Nando de Freitas (Google Deepmind, University of Oxford) και Shimon Whiteson (University of Oxford), και δουλεύουν πάνω στο trending field του Deep Learning.
 «Η τελευταία μας δουλειά», λέει στο LIFO.gr, «ήταν πάνω στην επίλυση προβλημάτων επικοινωνίας και συνεργασίας σε περιβάλλοντα με πολλά ρομπότ (agents).Για να το δοκιμάσουμε βάλαμε πολλαπλά AI να λύσουν γρίφους που χρησιμοποιούνται σε interviews εταιρειών όπως η Google και η Goldman Sachs.Μέχρι σήμερα, η τεχνητή νοημοσύνη έχει καταφέρει να κατακτήσει single-layer games, όπως Atari, Go κ.α.. Αυτή είναι η πρώτη φορά που οι agents μαθαίνουν μόνοι τους να επικοινωνούν και μαζί να λύνουν περίπλοκα προβλήματα.»
«Η τελευταία μας δουλειά», λέει στο LIFO.gr, «ήταν πάνω στην επίλυση προβλημάτων επικοινωνίας και συνεργασίας σε περιβάλλοντα με πολλά ρομπότ (agents).Για να το δοκιμάσουμε βάλαμε πολλαπλά AI να λύσουν γρίφους που χρησιμοποιούνται σε interviews εταιρειών όπως η Google και η Goldman Sachs.Μέχρι σήμερα, η τεχνητή νοημοσύνη έχει καταφέρει να κατακτήσει single-layer games, όπως Atari, Go κ.α.. Αυτή είναι η πρώτη φορά που οι agents μαθαίνουν μόνοι τους να επικοινωνούν και μαζί να λύνουν περίπλοκα προβλήματα.»
Η δημοσίευσή τους έλαβε ιδιαίτερη προσοχή από τον Βρετανικό τύπο (The Independent, New Scientist κ.α.) καθώς είναι η πρώτη φορά που μοντέλα τεχνητής νοημοσύνης μαθαίνουν από μόνα τους πρωτόκολλα επικοινωνίας για να λύσουν τόσο απαιτητικά προβλήματα. Ως συγγραφέας της δημοσίευσης, μαζί με τον Jakob Foerster, ο Γιάννης Ασσαέλ μου εξήγησε όσα διάβασα -και αρχικά δεν κατάλαβα. (Με δυο λόγια: Μοντέλο Τεχνητής Νοημοσύνης (AI) καταφέρνει να λύσει έναν από τους πιο συνήθεις γρίφους από συνεντεύξεις της Google και της Goldman Sachs.)
Η ομάδα του πανεπιστήμιου της Οξφόρδης, του Canadian Institute for Advanced Research και της Google DeepMind, μοντελοποίησε και έλυσε, μεταξύ άλλων, τον γρίφο των “100 καπέλων” χρησιμοποιώντας “Deep Distributed Recurrent Q-Networks”.
«Πιστεύουμε πως η πρόκληση τώρα είναι να αποκτήσουμε καλύτερη κατανόηση των πρωτοκόλλων επικοινωνίας που αναπτύσσονται, και να δοκιμάσουμε την μέθοδό μας σε πραγματικές καταστάσεις»
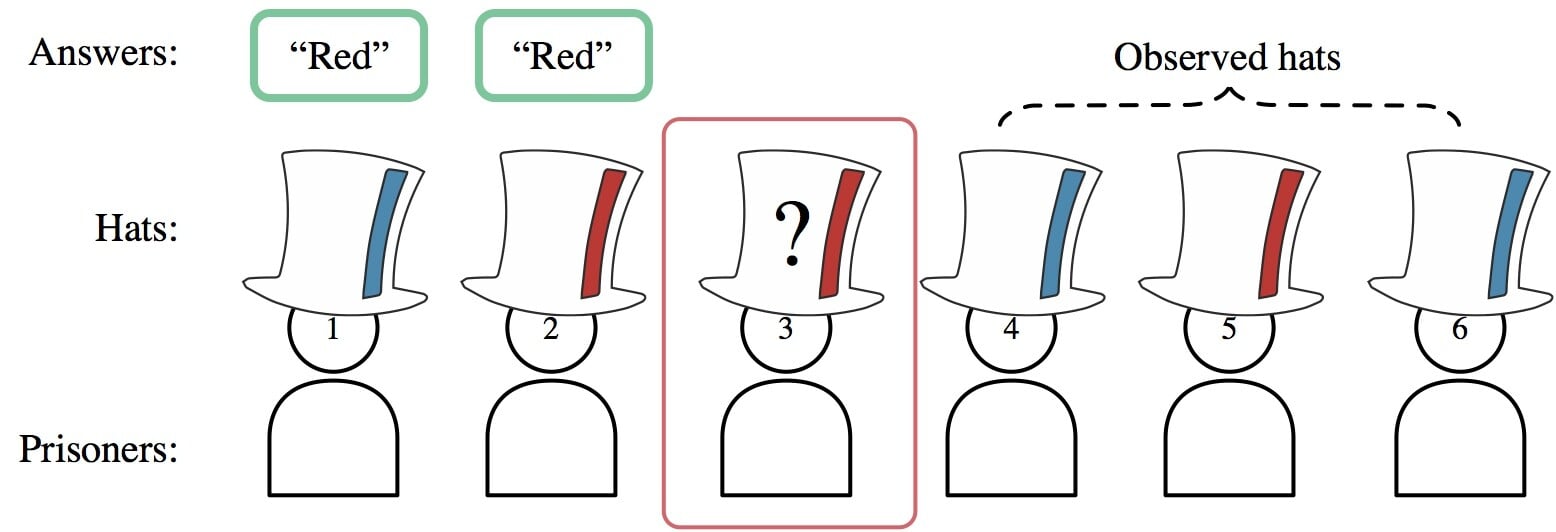
Ο γρίφος έχει ως εξής: 100 κρατούμενοι στέκονται σε μια σειρά, ο ένας μπροστά από τον άλλο, φορώντας μπλε η κόκκινο καπέλο. Κάθε ένας μπορεί να ακούσει τις απαντήσεις των πίσω του και να δει τα χρώματα των καπέλων μπροστά του, αλλά όχι το δικό του ούτε των πίσω. Ένας φρουρός αρχίζει να ρωτάει τους κρατούμενους από πίσω με την σειρά το χρώμα του καπέλου τους, και για να “ελευθερωθούν” πρέπει να το μαντέψουν σωστά.
Πριν τοποθετηθούν σε τυχαία σειρά, μπορούν να συνεννοηθούν και να βρούνε μια στρατηγική που θα εξασφαλίσει την ελευθερία (σχεδόν) όλων τους.
Ο Ασσαέλ παραθέτει: «Η λύση που προτείνουμε μοντελοποιεί τον κάθε κρατούμενο ως ένα ξεχωριστό Νευρωνικό Δίκτυο, και όλα μαζί καταφέρνουν να βρουν την βέλτιστη στρατηγική. Η δουλειά μας ανοίγει τον δρόμο για μια νέα κατηγορία προβλημάτων συντονισμού και επικοινωνίας πολλαπλών πρακτόρων (agents)», ενώ ο συγγραφέας Jakob Foerster παραθέτει: «Τα αποτελέσματα μας δείχνουν ότι μπορούμε να μοντελοποιήσουμε δύσκολα προβλήματα ακόμα και για ανθρώπους, ως προβλήματα επικοινωνίας με τεχνητή νοημοσύνη και να λυθούν με την μέθοδο που προτείνουμε.»
Η καλύτερη στρατηγική του μοντέλου, βασίζεται σε parity coding και σώζει τους 99 κρατούμενους, δίνοντας 50% πιθανότητα επιτυχίας στον πρώτο στην σειρά. Για να συμβεί αυτό ο πρώτος κρατούμενος θα μαντέψει "μπλε" αν ο αριθμός των "μπλε" καπέλων που βλέπει είναι ζυγός, και "κόκκινο" αν είναι μονός. Έτσι ο επόμενος στην σειρά μπορεί να το συγκρίνει με τον αριθμό των "μπλε" καπέλων που βλέπει αυτός και να μαντέψει σωστά το χρώμα του δικού του.
«Πιστεύουμε πως η πρόκληση τώρα είναι να αποκτήσουμε καλύτερη κατανόηση των πρωτοκόλλων επικοινωνίας που αναπτύσσονται, και να δοκιμάσουμε την μέθοδό μας σε πραγματικές καταστάσεις» λένε οι συγγραφείς του επιστημονικού άρθρου, το οποίο είναι ολόκληρο διαθέσιμο εδώ.