


Σκοπός αυτής της νέας στήλης είναι η απάντηση ερωτημάτων επιστημονικής και τεχνολογικής αφόρμησης. Τα ερωτήματα αυτά θα προκύπτουν είτε από την τρέχουσα ειδησεογραφία, είτε από δική σας έμπνευση στα σχόλια. Δοκιμάζω την εισαγωγή σε αυτή τη νέα προσπάθεια επιχειρώντας να απαντήσω στο εξής ερώτημα:
Για ποιο λόγο θεωρείται τόσο σημαντική η νίκη της τεχνητής νοημοσύνης στο Go;
Το αρχαίο κινεζικό παιχνίδι στρατηγικής Go παίζεται με δύο παίκτες, οι οποίοι τοποθετούν εναλλάξ άσπρα και μαύρα πούλια (πέτρες) σε ένα πίνακα (γκόμπαν) διαστάσεων 19 x 19. Ο στόχος είναι να περικυκλώσεις όσο το δυνατόν μεγαλύτερη ακάλυπτη περιοχή, προσπαθώντας ταυτόχρονα να προστατεύσεις τα πούλια σου και να εγκλωβίσεις του αντιπάλου. Ως εδώ το παιχνίδι μοιάζει γελοία απλό και σε καμία περίπτωση δεν προδίδει το βάθος περιπλοκότητας μιας εξελισσόμενης παρτίδας. Για ποιο λόγο, λοιπόν, αποδεικνύεται τόσο δύσκολο και η νίκη μιας υπολογιστικής μηχανής έναντι του ανθρώπου άργησε 19 χρόνια μετά την περίφημη νίκη που σημείωσε ο υπολογιστής Deep Blue στο σκάκι; Η απάντηση κρύβεται σε απλά μαθηματικά.
Ενώ στο σκάκι έχεις τη δυνατότητα να επιλέξεις ανάμεσα σε 35-40 διαφορετικές κινήσεις ανά πάσα στιγμή, στο Go έχεις ένα εύρος 250. Ο αριθμός αυτός ονομάζεται παράγοντας διακλάδωσης και προσδιορίζει το εύρος των επιλογών που έχει ο παίκτης. Κάθε διαφορετική επιλογή οδηγεί σε ένα νέο εύρος επιλογών και η διαδικασία επαναλαμβάνεται, αυξάνοντας εκθετικά τον αριθμό σε βάθος επόμενων κινήσεων. Πχ, στη δεύτερη κίνηση προκύπτουν 62.500 διαφορετικές κινήσεις και στην τρίτη 15.625.000. Συγκριτικά με το σκάκι, ο αριθμός των διαφορετικών παρτίδων εκτιμάται ότι επισκιάζει τον αριθμό των ατόμων στο παρατηρήσιμο σύμπαν, ενώ ο αντίστοιχος για το Go εκτινάσσεται κατά έναν παράγοντα τρισεκατομμύρια τρισεκατομμυρίων (...) - και πιο συγκεκριμένα τη μονάδα ακολουθούμενη από 170 μηδενικά! Γι' αυτό και άργησαν τόσο οι προγραμματιστές να σημειώσουν πρόοδο. Είναι αδύνατο να εκμεταλλευτούν τη θηριώδη υπολογιστική ισχύ των δισεκατομμυρίων πράξεων ανά δευτερόλεπτο, για να αξιολογήσουν σε πεπερασμένο και λογικό χρόνο το ασύλληπτα μεγάλο εύρος των πιθανών κινήσεων. Βεβαίως, ο ανθρώπινος εγκέφαλος ακολουθεί μια εντελώς διαφορετική στρατηγική, η οποία βασίζεται σε ενστικτώδη διαίσθηση του πως μοιάζει μια καλή βαριάντα, διακρίνοντας τα επιμέρους μοτίβα.
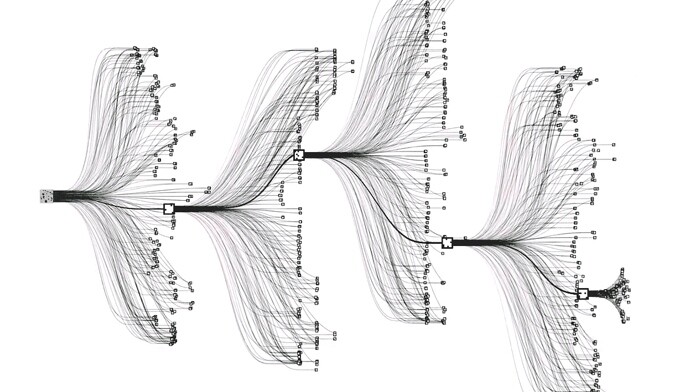
Το πρόγραμμα AlphaGo, που ανέπτυξε η βρετανική εταιρία τεχνητής νοημοσύνης DeepΜind [η αποία αποκτήθηκε πέρυσι από τη Google για το ευκαταφρόνητο ποσό των 500 εκ. δολαρίων, σε σύγκριση με την περίπτωση των 16 δισ. του WhatsApp] νίκησε τον παγκόσμιο πρωταθλητή του Go, Lee Sedol, επιτυγχάνοντας σκορ 4-1. Πάλι καλά που ο περήφανος πρωταθλητής νίκησε μία φορά, διασώζωντας λίγη απ' την αξιοπρέπεια της ανθρωπότητας μπροστά στα φοβερά δημιουργήματα της. Ουσιαστικά, αυτό που κατάφερε το AlphaGo είναι να μιμηθεί τη διαδικασία ενστικτώδους διαίσθησης που αποκτά ένας καλός παίκτης, για το πως μοιάζει μία καλή τοποθέτηση στο επιτραπέζιο. Ο αλγόριθμος έπειτα από ενδελεχή μελέτη παρτίδων ανθρώπινων παικτών, απέσπασε τους κανόνες που ούτε οι ίδιοι οι κορυφαίοι παίκτες είναι σε θέση να εξηγήσουν ρητά. Στη συνέχεια, οι προγραμματιστές έβαλαν τον αλγόριθμο να παίξει παρτίδες Go με αντίπαλο τον εαυτό του, εξωθώντας τον σε μία μακρά διαδικασία αυτοβελτίωσης.
Πλέον, ούτε οι ίδιοι γνωρίζουν τα στρατηγικά μυστικά που εκμεταλλεύτηκε ο αλγόριθμος για να επιτύχει τις νίκες του. Μάλιστα, κάποιες από τις κινήσεις που επέλεξε αρχικά μοιάζουν εντελώς άσκοπες, μόνο για αποδειχθεί ότι στη συνέχεια συνεισέφεραν σημαντικά στο πλεονέκτημα που απέκτησε πριν τις νίκες. Θα μπορούσε ο αλγόριθμος να διαθέτει ένα είδος νοημοσύνης που δε γίνεται αντιληπτό από ανθρώπινους παίκτες; Ουδείς οίδε.
Στα πιο σημαντικά, το AlphaGo βασίζεται σε αρχές οργάνωσης που συναντώνται στην αρχιτεκτονική των νευρωνικών δικτύων, επομένως δύναται να μιμηθεί τις διαδικασίες μάθησης που λαμβάνουν χώρα στον ανθρώπινο εγκέφαλο. Το επιτευγμα θεωρείται υψηλής αξίας γιατί μπορεί να έχει ευρεία εφαρμογή σε κλάδους που μέχρι πρότινος μόνο η ανθρώπινη νοημοσύνη μπορούσε να αντεπεξέλθει. Βεβαίως, ο υπεύθυνος του εργαστηρίου τεχνητής νοημοσύνης του Facebook, Yann LeCunn, έσπευσε να μειώσει το βεληνεκές του επιτεύγματος, σχολιάζοντας πως η διαδικασία μάθησης βασίστηκε σε παρτίδες ανθρώπινων παικτών... αν αφηνόταν ο αλγόριθμος να μάθει μόνος του, τι θα κατάφερνε στο τέλος;
Σε επόμενο άρθρο:
- Υπάρχουν τα γονίδια της ευφυίας;
- Πώς ο ανθρώπινος εγκέφαλος παράγει τα όνειρα;
- Δύναται η τεχνολογία του bitcoin να αλλάξει τις ζωές δισεκατομμυρίων;
Αν ενδιαφέρεστε για τα πιο πρόσφατα άρθρα μου, έχετε ερωτήσεις ή επιθυμείτε να μου προτείνετε ένα θέμα, μπορείτε να με ακολουθήστε στο Facebook και να επικοινωνήσετε μαζί μου.

























σχόλια